The narrative that 'we don’t understand AI' remains a persistent theme across the industry. Dario Amodei, the CEO of Anthropic, wrote in a recent essay titled “The Urgency of Interpretability” that “people outside the field are often surprised and alarmed to learn that we do not understand how our own AI creations work.” Another recent blog by IBM’s Matthew Kosinski on black box models states that “their own creators do not fully understand how they work.” Even the New York Times published an article,“We Don’t Really Know How A.I. Works. That’s a Problem,” that traces how interpretability researchers at Anthropic, Goodfire, Google DeepMind, and elsewhere are still struggling to map even small parts of these systems, with one Google DeepMind lead admitting he had grown disillusioned with a popular technique after a year of focused work on it. This produces a paradoxical image where the very people driving these leaps in performance claim they don't understand how their own models work.
Interestingly, it's the language models’ greatest naysayers who argue that we fundamentally do not understand how they work. Yann LeCun, the former VP & Chief AI Scientist at Meta, believes that models “regurgitate approximately whatever they were trained on from public data” and has founded a startup called AMI Labs to look for entirely new architectures. When Emily Bender, Timnit Gebru, and their co-authors wrote their influential 2021 paper “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” they claimed that LLMs are essentiallystochastic parrots, stitching linguistic forms together statistically without any underlying understanding. At first glance, these positions look irreconcilable: one group claims the systems are opaque even to the people who build them, the other says there's nothing opaque about them at all. But both can be true at once.
Known architecture, unknown outcomes
Much like physicists and chemists understand how molecules work and interact at the atomic level, AI researchers have a complete understanding of the fundamental building blocks of language models. We have strong justifications for the various mathematical operations that make up language models, the algorithms they use, and the infrastructure they run on. We also understand that we're using an architecture that is extremely expressive, which, in theory, can learn a wide variety of functions if “large” enough. The universal approximation theorem tells us that even a feedforward network with a single hidden layer can approximate any continuous function on a compact subset of ℝⁿ to arbitrary precision, provided it has sufficient width and a suitable non-linear activation. Modern deep networks extend this property dramatically, making the hypothesis class of current networks enormous.
However, what these models learn can be so complex that, even though we understand how they operate and learn, we struggle to grasp what they've actually learned. Natural language is one such area that requires large models and enormous amounts of data to capture the underlying function. We understand the construction, the building blocks, and the training data, but the function underlying language is complex enough that once a model has been trained to approximate it, we cannot provide a complete explanation of why the model follows certain behavior patterns.
This ties into a larger pattern in which we cannot predict a system's attributes as it grows. Researchers describe such properties as emergent, and they show up across the sciences whenever systems grow exponentially in scale.
Emergent systems
Understanding larger systems has proven a longstanding challenge across many scientific fields. In his seminal 1972 Science essay “More is Different,” Nobel laureate P.W. Anderson made a point that now extends naturally into the field of artificial intelligence:
“It seems inevitable to go on uncritically to what appears at first sight to be an obvious corollary of reductionism: that if everything obeys the same fundamental laws, then the only scientists who are studying anything really fundamental are those who are working on those laws. In practice, that amounts to some astrophysicists, some elementary particle physicists, some logicians and other mathematicians, and a few others. The main fallacy in this kind of thinking is that the reductionist hypothesis does not by any means imply a "constructionist" one: The ability to reduce everything to simple fundamental laws does not imply the ability to start from those laws and reconstruct the universe.”
An understanding of particles does not mean we can extrapolate from there to arrive at planetary bodies, living organisms, or complex societies. Despite extensive study of cells and neurons, we still do not fully understand the human brain. The same gap separates our grasp of a transformer's individual operations from our grasp of what a trained model actually knows.
Scaling these models reliably improves them, but it doesn't follow that more scale will "emerge" something like superintelligence. We're already operating at a scale where the people training these systems can't fully describe the shape of the function being learned, and so can't say with confidence where the bounds of performance lie. That is what made the forecasts built around AI arriving by 2027 hard to take at face value, and their authors, who always framed 2027 as a most-likely scenario rather than a firm prediction, have since revised their median estimates later. Tellingly, they did so not because something inexplicable happened but because measurable progress on tasks like autonomous coding came in slower than expected: a reminder that our ability to extrapolate from current trends is weak in both directions. Maybe scaling existing architectures will produce large leaps in intelligence, as the foundation labs hope. But it could just as easily plateau, or emerge with something no one anticipated. This uncertainty is why even the researchers closest to these systems sharply disagree about what comes next.
New approaches to interpretability
Because language models are so complex, researchers have long relied on other models to interpret and explain what foundation models produce. One new approach from Anthropic leverages Natural Language Autoencoders to explain particular outputs. Unlike their previous research on Sparse Autoencoders, which attempted to uncover which features LLMs learned during training, this research provides information on a point-by-point basis.
When given a model's internal states for a particular output, NLAs provide a natural language explanation for why the model responded to a prompt in a particular way. To do so, the NLAs are trained to take a model’s internal state as input and produce a description of the input to the model and the output produced. The training works by pairing this verbalizer with a second model, the activation reconstructor, which tries to recover the original internal states from this natural-language description alone. For the description to be good enough to help rebuild the internal states, it must contain real information about what the model was representing at that moment.
These spot explanations can be useful for a number of investigative tasks. During Anthropic's pre-deployment audit of Claude Opus 4.6, NLAs surfaced cases where the model internally suspected it was being evaluated without ever saying so, and helped trace odd behaviors such as the model spontaneously switching to Russian when prompted in English. Researchers have also used NLAs to causally alter model behavior: by editing the natural-language explanation of an internal state and feeding the edited version back through the reconstructor, they can derive a steering vector that predictably changes what the model outputs.
This new approach helps us generate hypotheses about model behavior more reliably than it settles them. It's a practical addition to the interpretability toolkit, but still falls short of revealing the full nature of the functions these models have learned.
The ongoing debate
Many of the seemingly conflicting claims are not mutually exclusive. Amodei's statement that we don’t fully understand how models work refers to the extremely complex function that the model has learned. Even so, we’ve conducted many studies of trained models that show they statistically mimic their training data (the stochastic parrot). This has led researchers like Yann LeCun to look elsewhere for future developments.
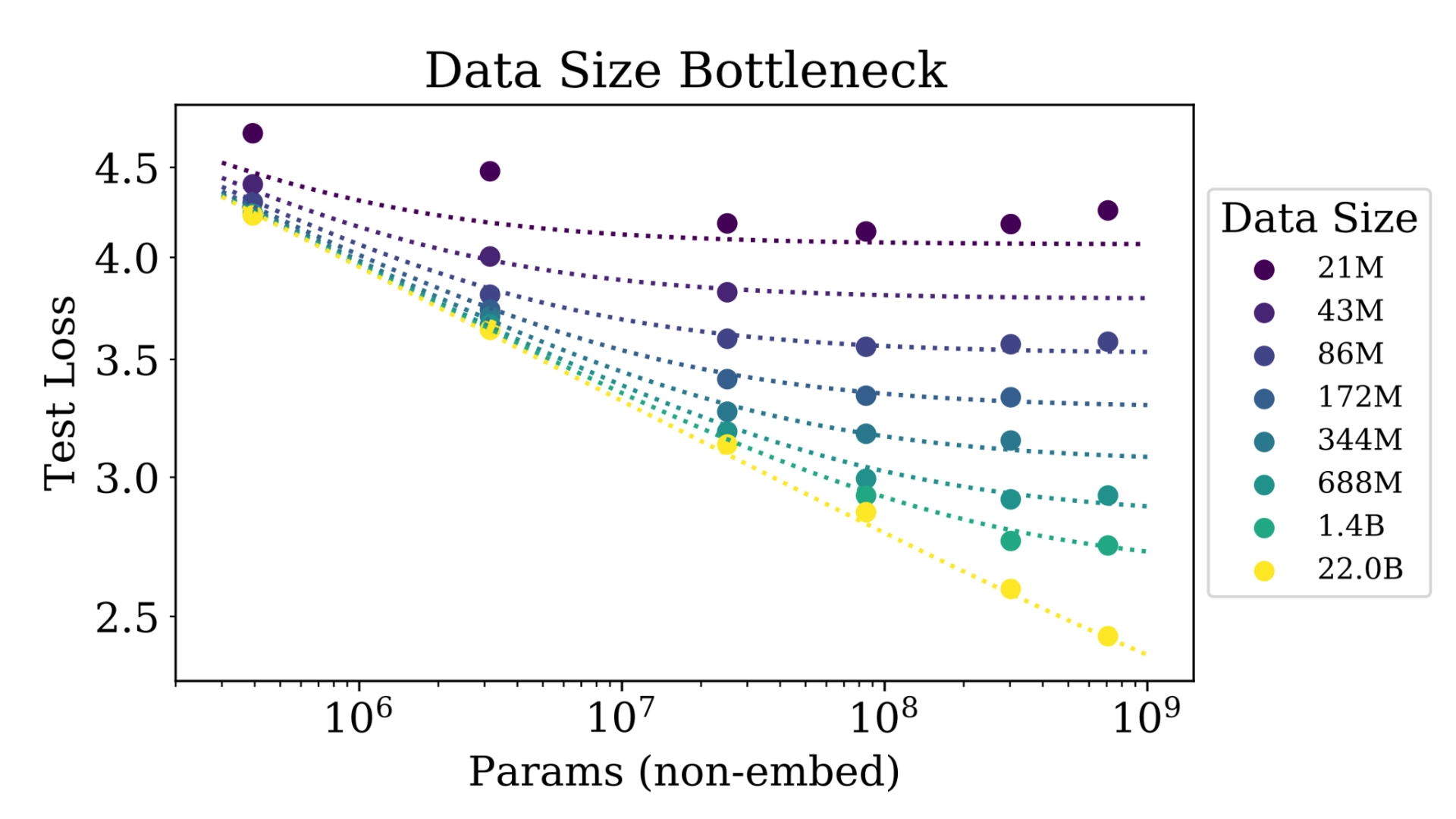
On the other hand, research at OpenAI has shown that increasing the size and amount of training data of these models correlates with increased performance. This simple finding has led to massive scaling and, correspondingly, large performance leaps we’ve seen from AI labs.
Model performance scales predictably with size and data
*Figure adapted from Kaplan et al., "Scaling Laws for Neural Language Models," arXiv:2001.08361 (2020).
We cannot say whether current scaling trends will continue, given the compute and data limitations we've begun to encounter. Even if we had unlimited data and compute, we cannot predict whether another leap in parameter size would produce superintelligence, because emergent properties are by their nature unpredictable. What we do have is a fundamental understanding of the building blocks that compose these systems, a growing body of interpretability work that has identified real internal structure, and a clear empirical record that scaling has, so far, improved performance.
*Portfolio company founders listed above have not received any compensation for this feedback and may or may not have invested in a SignalFire fund. These founders may or may not serve as Affiliate Advisors, Retained Advisors, or consultants to provide their expertise on a formal or ad hoc basis. They are not employed by SignalFire and do not provide investment advisory services to clients on behalf of SignalFire. Please refer to our disclosures page for additional disclosures.
Subscribe to our newsletter
We typically send no more than 4-6 newsletters/yr with helpful tips on company building, our perspectives on industry trends, and event invites.
Flatter, leaner, more technical - The new shape of tech companies in 2026. Read SignalFire's 2026 State of Tech Talent Report to discover how AI is reshaping tech hiring, why engineers are more in demand, and how the modern org chart is flattening.
Read more
AI/ML
Investment Thesis
Developers
Must-Read
Practitioner’s Perspective
June 3, 2026
The 4 arguments for the death of software, ranked from worst to best
Is software dead? Are we in an AI bubble? SignalFire's CTO, Ilya Kirnos, ranks the 4 arguments driving the "SaaSpocalypse" and breaks down where true defensibility and enterprise tech moats live now.
Read more
AI/ML
Developers
Investment Thesis
May 4, 2026
Moats are for castles: A new argument for permanence over defensibility in AI startups
Stop manufacturing premature moats. This post argues that AI startups should prioritize permanence over defensibility. Learn why real moats are earned by solving persistent problems that endure even when intelligence is a cheap commodity. (188 characters)
Read more
AI/ML
Investment Thesis
Developers
Must-Read
Practitioner’s Perspective
June 3, 2026
The 4 arguments for the death of software, ranked from worst to best
Is software dead? Are we in an AI bubble? SignalFire's CTO, Ilya Kirnos, ranks the 4 arguments driving the "SaaSpocalypse" and breaks down where true defensibility and enterprise tech moats live now.
Read more
AI/ML
Developers
Investment Thesis
May 4, 2026
Moats are for castles: A new argument for permanence over defensibility in AI startups
Stop manufacturing premature moats. This post argues that AI startups should prioritize permanence over defensibility. Learn why real moats are earned by solving persistent problems that endure even when intelligence is a cheap commodity. (188 characters)
Read more
Investment
AI/ML
Investment Thesis
November 4, 2025
Why expert data is becoming the new fuel for AI models
As the open web runs out of usable data, the next frontier of AI training lies in expert knowledge. Learn why the future of AI depends on high-quality, domain-specific data and how startups curating expert workflows are becoming the new power brokers of the AI economy.
By clicking “Accept”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. View our Privacy Policy for more information.