
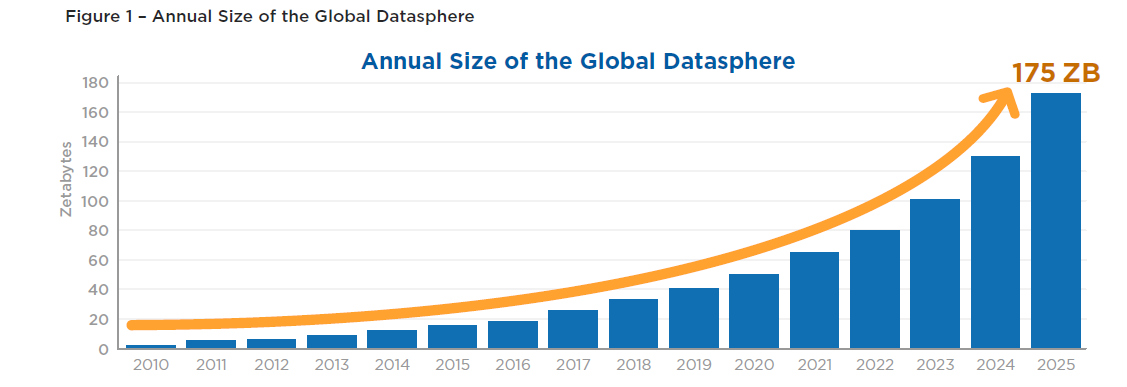
We are in the midst of a data explosion – almost everything we touch and work with today generates data. Reports estimate that in 2020, each person generated 1.7 MB of data every second through social media, email/other communication, videos, and that number is only increasing. 90% of the world’s data was produced in the last two years alone. The International Data Corporation estimates the global datasphere will grow from 64 zettabytes (1 zettabyte = 1 trillion gigabytes) in 2020 to over 175 by 2025.
And this explosion of data isn’t just in volume. It’s in complexity, all driven by new sources and types of data, new technologies, and changes in how consumers and businesses interact. These shifts came with the promise of unprecedented insights. If companies could stitch together and analyze this data, they could move from gut-based decision-making to being data-driven. This would help them deliver superior consumer experiences, significant top-line revenue growth, and increased bottom-line savings.
To capitalize on this, companies like Amazon, Facebook, and Google built huge, expensive teams to extract meaning from their data. But most organizations on tighter budgets have hit a roadblock: the data scientist shortage.
Had the world foreseen the simultaneous explosion in data volume and complexity as well as its lucrative application, we would have trained enough data scientists to make them readily available and affordable to businesses of all sizes. Instead, the relatively few with the skills necessary are in such high demand that salaries have ballooned and companies can’t hire enough. Turning data into insights is still highly manual today. The result is a problematic bottleneck, where companies waste time waiting for their slim data science teams to analyze new opportunities for improvement or miss them altogether.
The current analytics process often starts with a business user coming up with a hypothesis on what might be a meaningful insight within their data. They must then work with a data scientist to gather and combine that data into a well-structured format. Half of all data science work today is actually spent preparing data, and frequently ends with most of the data ending up pushed aside. After weeks to months of upfront work, data scientists can finally test if there was indeed a statistically significant conclusion in that data. If not, they must restructure the underlying data or start over altogether.
This manual process, combined with the talent shortage, has driven a significant gap between data science supply and demand. QuantHub estimates the 2020 data scientist shortage was 250,000. Businesses can’t wait for education to bridge that gap. They need a way to take data scientists out of the equation.
Enter Unsupervised. Unsupervised’s AI automatically analyzes their customer’s data and discovers the most significant opportunities and problems.

The platform does not require users to have data science backgrounds. It ingests raw data directly from sources, automatically prepares and analyzes the data, identifies any statistically relevant patterns, and ranks them based on impact to business KPIs (sales increases, customer churn, etc.). Business users can then directly review and operationalize those insights. Through this unprecedented volume and velocity of business insights, all business owners can find and respond to new opportunities and risks.
Unsupervised solves the data science crisis through AI, enabling non-technical business users to directly identify and respond to opportunities to optimize top-line growth, customer acquisition, and profitability. Unsupervised, plus a more affordable and plentiful business-team member, can replace the role of a data scientist.
We could not be more excited to be a part of Unsupervised’s $35M Series B and leverage our own AI expertise to support the team as they build an enduring automated analytics franchise.

SignalFire understands the value of data science because it’s what we’re built on. Roughly one-fifth of our team are AI PhDs, data scientists, and engineers. They work on constantly improving our Beacon technology which crunches a half-trillion data points to rank the skill and hireability of hundreds of millions of the most talented workers in technology. This is how we made 1000 job candidate intros to our portfolio in just one year. The team also refines our Beacon competitive intelligence engine, which sees about 4% of US credit card transaction data to help our portfolio companies assess macroeconomic trends, monitor competitors’ businesses, and optimize their own pricing.
But most organizations don’t have the resources to hire this kind of talent. With our investment in Unsupervised, we want to help democratize access to data science. We’re proud to support Noah Horton and his team at Unsupervised’s mission to help every company afford to better understand their business.
Subscribe to SignalFire's newsletter for guides to startup trends, fundraising, and recruiting

Jonathan Lim
Partner
Jon joined SignalFire in 2020 where he's now a Partner that focuses on venture and growth-stage investments. Before SignalFire, Jon helped build KKR’s Next Generation Technology Fund.



